How a bizarre training curve called "grokking" revealed that neural networks learn nothing — until suddenly, they learn everything.
What's Inside the Black Box?
Look at this image.

Five words go in: "The," "capital," "of," "France," "is." Each word gets converted into a strip of numbers — a token. Those tokens feed into a neural network (in this case, Meta's Llama 3.2). And out the other side comes a single word: "Paris."
Inputs. Outputs. And in the middle, a billion tiny numbers multiplying and adding in ways nobody designed by hand.
We know it works. What we don't know — what kept researchers up at night for years — is how it learns to work in the first place. How does a pile of random numbers eventually figure out that the capital of France is Paris?
The answer involves one of the most surprising discoveries in modern AI. It's called grokking. And it broke almost everything we thought we knew about how neural networks learn.
The Expected Story: A Model That Memorized Everything and Learned Nothing
To understand why grokking was so shocking, you need to understand what researchers expected to happen.
When you train a neural network, you give it two things: a set of training examples (questions with known answers) and a set of test examples (new questions it's never seen). The goal is generalization — you want the model to learn the pattern, not just memorize the answers.
Think of a student preparing for an exam. If they memorize every practice problem word-for-word, they'll ace the practice test. But hand them a new problem they've never seen, and they're lost. That's memorization without understanding.
This is exactly what happens with small datasets. Give a neural network a handful of examples and it does the easy thing: it memorizes them like a lookup table. Ask it a training question? Perfect score. Ask it anything new? Nothing.
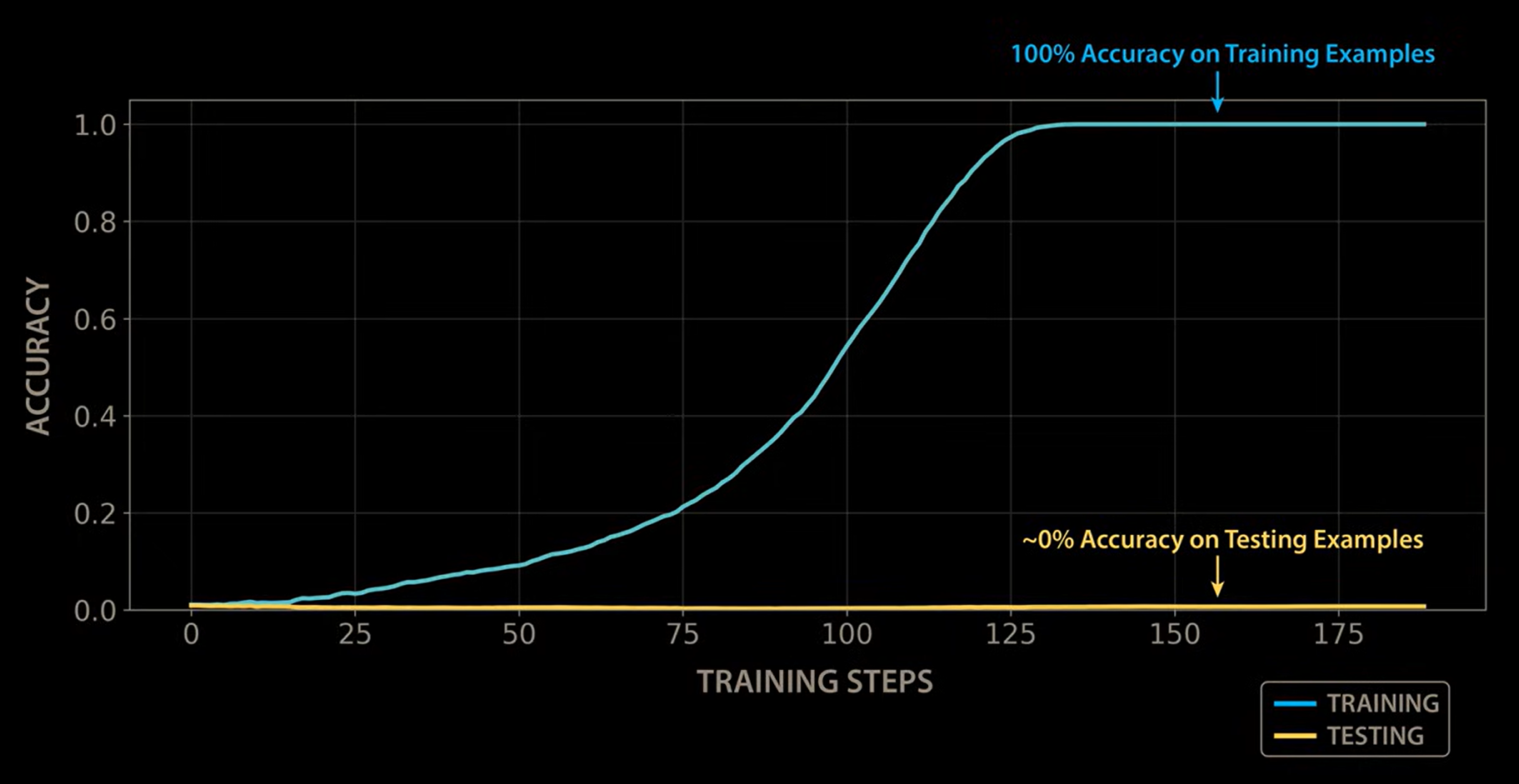
This chart shows exactly that. The blue line (training accuracy) rockets to 100% within the first few dozen steps. The yellow line (test accuracy) flatlines at zero. The model aced every question it had seen before. It understood absolutely nothing.
In machine learning, this is called overfitting — the textbook villain. And for decades, the conventional wisdom was clear: when you see this, stop training. The model overfit. It's a dead end. Move on.
So that's what researchers did. They stopped.
Until someone didn't.
The Discovery: What Happens When You Keep Going?
In 2021, a team of researchers at OpenAI was training small neural networks to do modular arithmetic — basically clock math. (Think: a 2-hour meeting starting at 11 a.m. ends at 1 p.m. That's 11 + 2 mod 12 = 1.) Their initial results were underwhelming. The models memorized the training data almost instantly, but performed terribly on new examples. Standard overfitting. Dead end.
Then, as the story goes, one of the researchers went on vacation — and accidentally left a model training.
When they came back, they were shocked. After thousands of additional training steps where nothing had appeared to happen — test accuracy flat at zero, the model apparently spinning its wheels — something extraordinary had occurred.
The test accuracy curve had exploded upward.
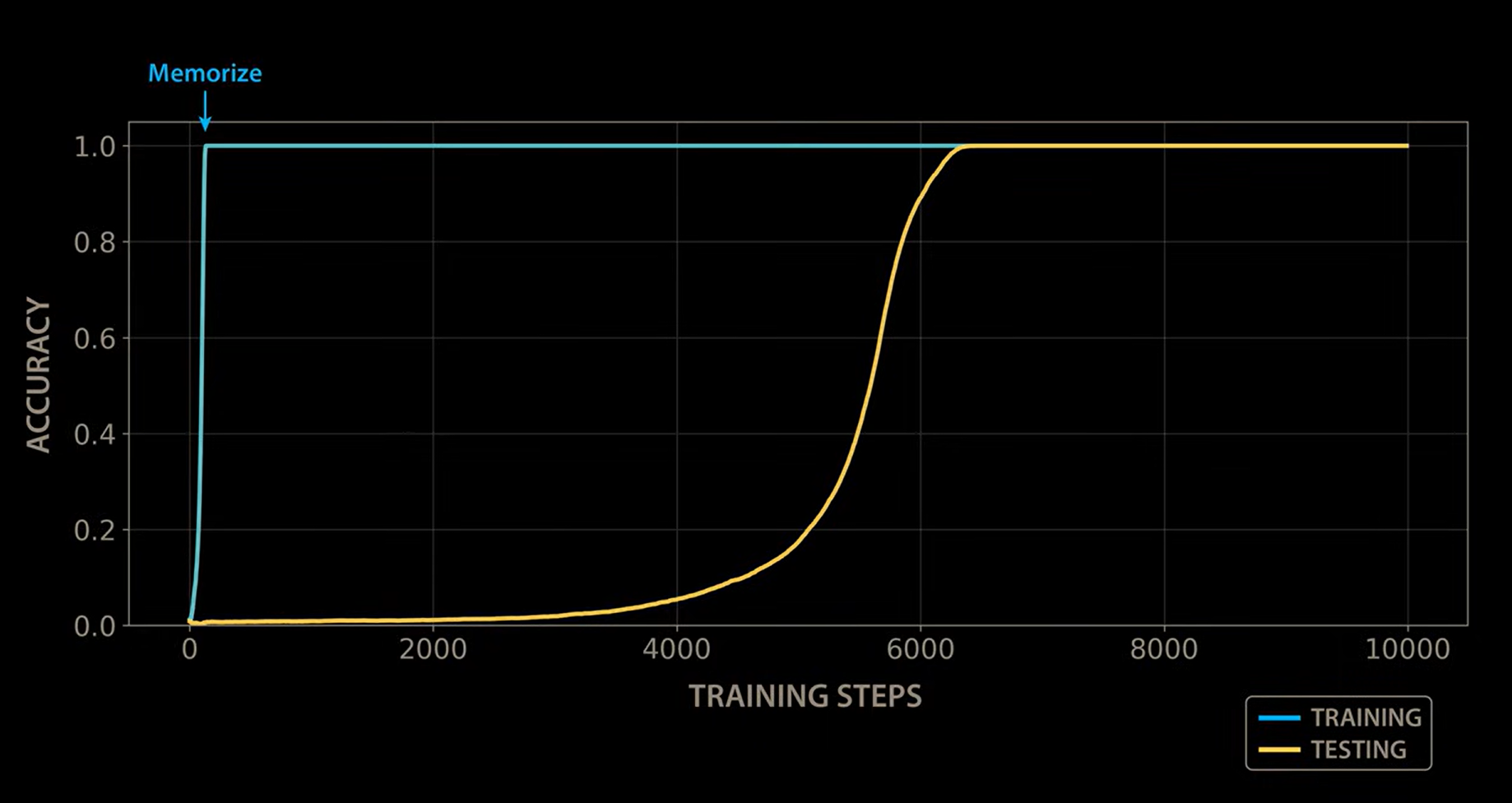
Look at that chart. The blue training line hits 100% almost instantly (top left). Then the yellow test line sits at zero for thousands of steps. Step 2,000. Step 4,000. Nothing. Flatline. And then somewhere around step 5,000 — it starts climbing. By step 7,000, it's at 100%.
The model went from understanding nothing to understanding everything. Not gradually. Not with a slow, steady climb. It just — clicked.
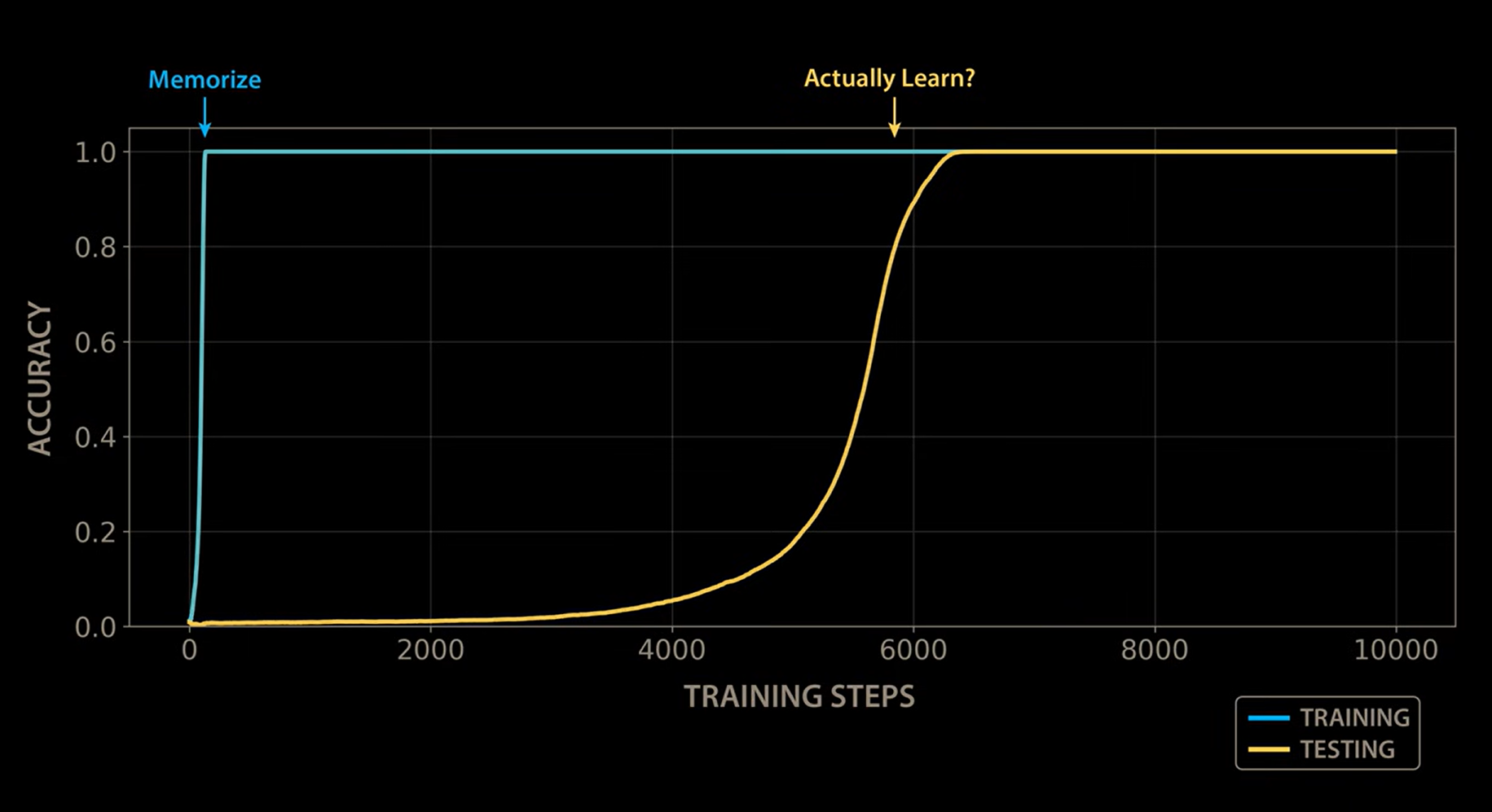
The annotations on this version of the chart capture it perfectly. The first phase is labeled "Memorize" — that's the instant jump to perfect training accuracy. The second phase, thousands of steps later when test accuracy finally erupts, is labeled with a question: "Actually Learn?"
The team replicated this sudden generalization across a range of arithmetic operations and model configurations, and in January 2022 published their findings. They named the phenomenon grokking, after a word coined by Robert Heinlein in his 1961 novel Stranger in a Strange Land. To "grok" something means to understand it so completely, so intuitively, that it becomes part of you. They chose this word because the network didn't just improve a little. It went from rote memorization to genuine comprehension in a sudden, dramatic leap.
This was one of the key turning points in how we understand neural networks. It challenged everything: when to stop training, what overfitting really means, and whether generalization requires more data — or just more patience.
Why This Matters: Three Assumptions, Shattered
Grokking didn't just add a new data point to the machine learning literature. It broke foundational assumptions that the field had operated on for years.
Assumption #1: If a model memorizes, it's done learning.
Wrong. Grokking showed that memorization isn't the end of the story — it's the beginning. During all those thousands of flat steps where test accuracy showed zero improvement, the model wasn't idle. It was silently reorganizing its internal structure. The outside looked frozen. The inside was transforming.
Assumption #2: Memorization and generalization are opposites.
Not exactly. The traditional view was binary: either your model memorizes (bad) or it generalizes (good). Grokking revealed something stranger — memorization can be a phase that precedes generalization. The model passes through memorization on its way to understanding. They're not opposites. They're stages.
Assumption #3: You can tell if training is working by watching the metrics.
Not always. During grokking, every external signal — loss curves, test accuracy, validation metrics — said "nothing is happening, stop wasting compute." But beneath that surface of apparent failure, the network was building something entirely new. The standard dashboard lied.
This discovery forced the field to reconsider what "learning" even means for a neural network. The model wasn't stuck. It was restructuring itself in ways that no metric could see — until suddenly, the restructuring was complete, and understanding emerged all at once.
What's Actually Happening Inside?
So what is happening during those silent thousands of steps?
The leading explanation goes something like this. When a network first encounters a small dataset, it finds the easiest solution: memorize. Build a lookup table. Input A maps to output B. This works perfectly on training data and requires minimal structural organization inside the network.
But if you keep training — and if you apply something called weight decay (a gentle pressure that penalizes complexity, nudging the network toward simpler solutions) — the lookup table starts to cost too much. Gradually, the network is forced to find a cheaper representation. A pattern. An algorithm.
In a 2023 paper, Neel Nanda and his collaborators used a technique called mechanistic interpretability to crack open a grokking network and reverse-engineer exactly what it had learned. What they found is stunning.
Remember, the task was modular arithmetic — clock math. And it turns out the network independently discovers trigonometry to solve it. In its very first layer, the model learns to compute the sines and cosines of its inputs. Deeper in the network, it takes products of these functions — cos(x) times cos(y), sin(x) times sin(y). And then something remarkable happens: these products combine in exactly the right way to produce cos(x + y). The network has effectively rediscovered a trigonometric identity — cos(x)cos(y) - sin(x)sin(y) = cos(x + y) — to convert multiplication into addition.
Nobody programmed trigonometry into this network. Nobody told it about cosines. The training data was just sparse patterns of inputs and outputs — meaningless numbers, as far as the model was concerned. And yet, through the pressure of continued training, it independently arrived at the same mathematical structure that humans formalized centuries ago.
As Welch Labs beautifully illustrates in their video on this topic, you can actually watch this happen.

Early in training, when the model is still just memorizing, the internal activations show no structure at all. But as training continues through that long flat period where nothing seems to be happening on the outside, clean sine waves and circular patterns slowly emerge inside the network — like watching an algorithm assemble itself from scratch.
The researchers even designed a new metric called excluded loss that strips out information at the key frequencies the model is learning. This metric climbs steadily during the "flat" period — proving that the model is making progress, building its Fourier-space solution piece by piece, even when every standard metric says nothing is happening.
This is extraordinarily rare in deep learning. Most of the time, the internals of a neural network are an unreadable tangle of numbers. Grokking gave us a window — arguably the clearest window we've ever had into how a transformer actually learns. Hence the title of Welch Labs' visualization: "the most complex model we actually understand."
The Bigger Picture
Here's what stays with you once you understand grokking.
We built machines that surprised us by memorizing everything they saw. Then those same machines surprised us again — by quietly, invisibly, transforming that memorization into genuine understanding. And the only reason we found out is that someone decided to keep the experiment running long past the point where every signal said to stop.
It makes you wonder: how many other discoveries are sitting on the other side of patience? How many experiments were stopped too early? How many models were thrown away one thousand training steps before they would have clicked?
Grokking changed how the field thinks about AI. Not because it solved a problem, but because it revealed that we didn't understand the problem in the first place. We thought we knew when a model was done learning. We were wrong.
AI researcher Andrej Karpathy once commented that training large language models feels less like building intelligence and more like summoning ghosts — fundamentally alien points in the space of possible minds. We communicate with these models in human language, but that's a thin veneer. One layer deeper, as grokking revealed, we find these systems independently rediscovering trigonometric identities and assembling Fourier-space algorithms that no human told them to build.
We started this post by looking at the black box from the outside — tokens in, answer out. Grokking gave us one of our first real glimpses of what happens inside that box during learning. And what we found was more surprising than anyone expected: a machine that memorizes, stalls, and then — in a sudden flash — understands.
Further Reading
- Welch Labs (2024). "The most complex model we actually understand" — The excellent video that inspired this post and from which the visualizations above are sourced. If you want to see the trig identity discovery animated step-by-step, start here.
- Power, A., Burda, Y., Edwards, H., Babuschkin, I., & Misra, V. (2022). "Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets." arXiv:2201.02177
- Nanda, N., Chan, L., Lieberum, T., Smith, J., & Steinhardt, J. (2023). "Progress Measures for Grokking via Mechanistic Interpretability." arXiv:2301.05217
- Heinlein, R. A. (1961). Stranger in a Strange Land. — The origin of the word "grok."
If this changed how you think about AI, share it with someone who still thinks neural networks are just pattern matching.